Let's dive: a tour of sync.Pool internals
In this post we will uncover what makes sync.Pool so damn good. You will get practical insights on how and when to use it.
Introduction
The Pool implemention of the sync package of Go’s standard library is a valuable asset to leverage. Deeply integrated with the runtime, it is an efficient way to lower allocations and relieve the garbage collector.
General usage
Let’s start by looking at the general lifecycle of items. When creating a new Pool, you give it a New func() any, that is responsible for allocating items. Consider the following:
package main
import (
"fmt"
"sync"
)
type JobState int
const (
JobStateFresh JobState = iota
JobStateRunning
JobStateRecycled
)
type Job struct {
state JobState
}
func (j *Job) Run() {
switch j.state {
case JobStateRecycled:
fmt.Println("this job came from the pool")
case JobStateFresh:
fmt.Println("this job just got allocated")
}
j.state = JobStateRunning
}
func main() {
pool := &sync.Pool{
New: func() any {
return &Job{state: JobStateFresh}
},
}
// get a job from the pool
job := pool.Get().(*Job)
// run it
job.Run()
// put it back in the pool
job.state = JobStateRecycled
pool.Put(job)
}
This code is a foolish example, as in real world you’d use a sync.Pool for items widely used through your application. This will make more sense as we get into how it works.
Here, on the call to pool.Get, the pool is empty, thus Get calls New and returns the newly allocated job. From our side, we could assume the item comes from the pool, but here we’re using the state attribute to differentiate newly allocated jobs from recycled ones - that’s one way to monitor cache miss in sync.Pool.
So we’ve got a job from the pool, we’ve ran it, now we want to put it back in the pool. We call the pool.Put method with the job, and it goes out of scope. The job is now safely splashing around in the pool, and you forget about it, until you need it again. Or maybe it won’t be there anymore - that’s what we will be discussing in next section.
Garbage Collection
Let’s say you have some kind of burst of activity, and you start allocating lots of jobs. Once the burst is over, you’ve offloaded a mountain of jobs to the pool, but there’s little chance you will need so many soon. That’s where sync.Pool starts to shine: it works hand in hand with the garbage collector to free unused jobs.
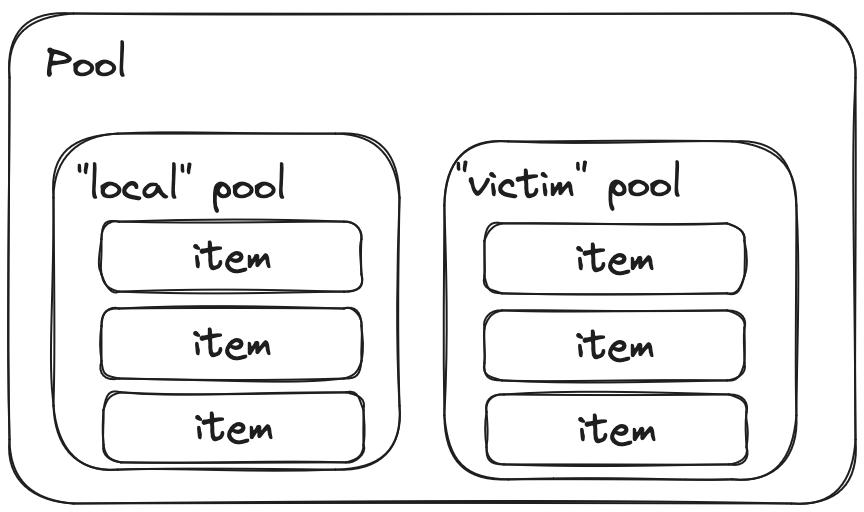
This is a simplified view of a Pool, we will get into more details later on. The first thing to note is that a Pool is actually composed of two distinct pools: local and victim. When calling Put, you are adding the item to local - and when calling Get, you are first looking into local, and if it is empty, you start looking into victim, and if that’s still not enough, you fallback to calling New. That’s not exactly right, but a good approximation for now.
The local pool is referred to as the primary cache, and victim is called the victim cache.
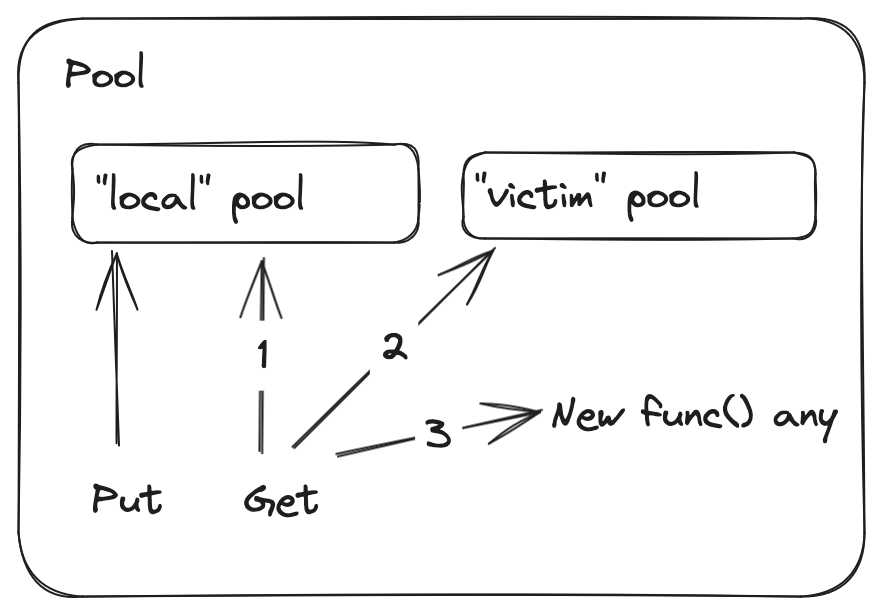
What comes out of this overly simplified explanation is that something has to move items from local to victim. That something is a static function called poolCleanup:
func poolCleanup() {
// This function is called with the world stopped, at the beginning of a garbage collection.
// It must not allocate and probably should not call any runtime functions.
// Because the world is stopped, no pool user can be in a
// pinned section (in effect, this has all Ps pinned).
// Drop victim caches from all pools.
for _, p := range oldPools {
p.victim = nil
p.victimSize = 0
}
// Move primary cache to victim cache.
for _, p := range allPools {
p.victim = p.local
p.victimSize = p.localSize
p.local = nil
p.localSize = 0
}
// The pools with non-empty primary caches now have non-empty
// victim caches and no pools have primary caches.
oldPools, allPools = allPools, nil
}
var (
allPoolsMu Mutex
// allPools is the set of pools that have non-empty primary
// caches. Protected by either 1) allPoolsMu and pinning or 2)
// STW.
allPools []*Pool
// oldPools is the set of pools that may have non-empty victim
// caches. Protected by STW.
oldPools []*Pool
)
func init() {
runtime_registerPoolCleanup(poolCleanup)
}
As you can see, the code for sync.Pool is well documented - but let’s break it down a little. The first thing to understand here is that all instanciated Pool objects are registering themselves into the allPools static variable on change. allPools references all pools for which local (the primary cache) is non-empty, and oldPools references all pools that may have non-empty victim caches.
On init, the poolCleanup static function is registered into the runtime. poolCleanup is called by the runtime prior to collecting garbage in a stop-the-world (STW) context, meaning nothing runs at the same time - the world is stopped.
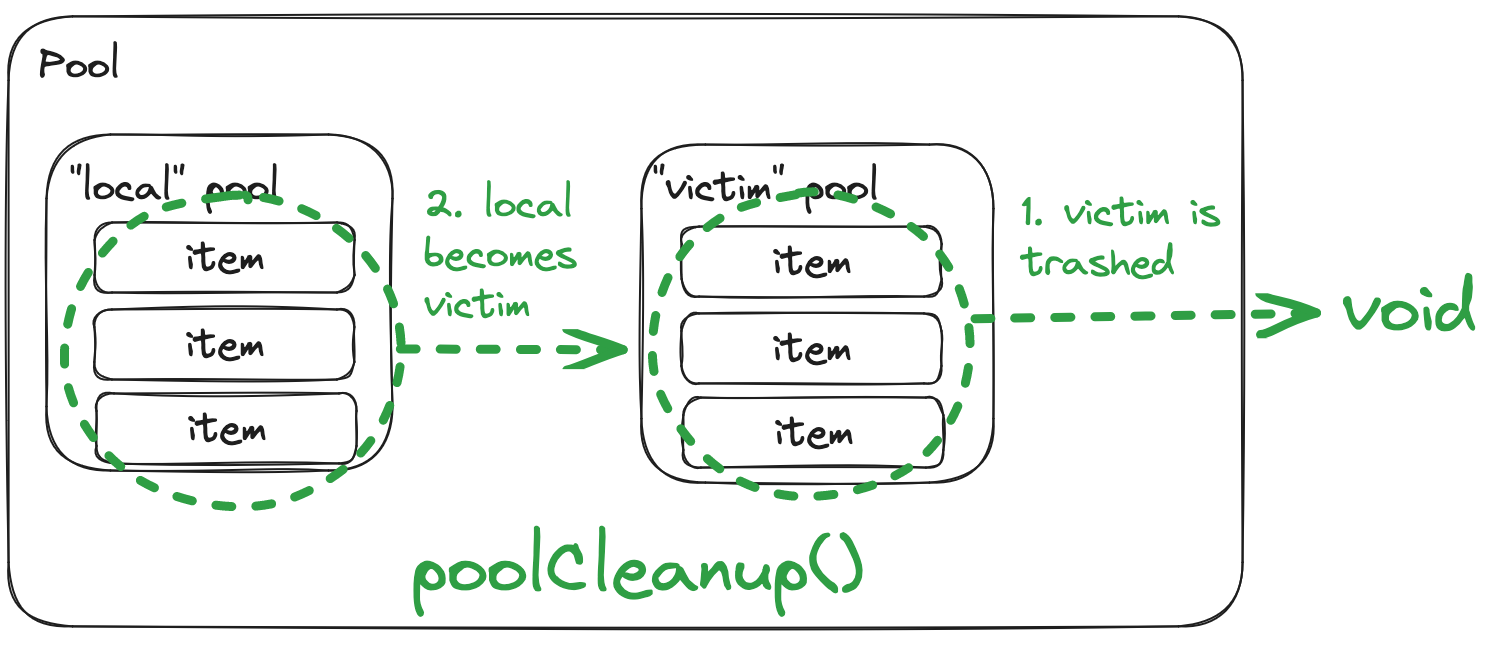
The poolCleanup function is very simple - it does one thing, and it does it great: victim is trashed, local becomes victim, and thus, pools from allPools are moved to oldPools, and allPools becomes empty.
In other terms, this means that items that have been in the pool for too long without being retrieved will eventually fade out. On the first garbage collection cycle, they will go from local to victim, and if they’re still not picked up, on the second cycle they will be trashed.
Proc pinning
So far, we know that a Pool is composed of two inner pools, local and victim. We know that they are of the exact same type, as they are continuously rolling from one to the other to void.
type Pool struct {
noCopy noCopy
local unsafe.Pointer // local fixed-size per-P pool, actual type is [P]poolLocal
localSize uintptr // size of the local array
victim unsafe.Pointer // local from previous cycle
victimSize uintptr // size of victims array
// New optionally specifies a function to generate
// a value when Get would otherwise return nil.
// It may not be changed concurrently with calls to Get.
New func() any
}
The first attribute noCopy serves a particular purpose - if you need a break, read my blogpost about it to know more.
We will get into details about what these pools actually are, but first, as you may have read in the comments, let’s talk about that “per-P” thing.
Here, we’ll need a very basic understanding of scheduling actors - if you’re not familiar with this, you definitely should look into it. There are three main actors : goroutines (G’s), machines (M’s), and Processors (P’s). These three rely upon each other to get work done. Goroutines are executed by machines, which represent OS threads. These machines, in order to do some work, first need to acquire a processor, which represent a CPU core. We can thus say that the P’s are the limited resource here; they are the limiting factor. Machines are fighting over a limited number of processors to run work.
Goroutines’ execution can be stopped at any time by the runtime in order to execute something else: this is preemption. Well, this is not exactly true: there are so-called “safe-points” where goroutines can be stopped in a clean state, and these are the only places where preemption can happen. But you are not in control of these safe-points - so it’s okay to assume it can happen anytime. It’s an interesting topic, but out-of scope here.
The act of proc pinning disables preemption: the P become ours, and ours only, until we unpin. In other words, our goroutine can safely assume it won’t be stopped, even by the GC, and that the P won’t be used by any other goroutine. Once pinned, the execution flow is uninterrupted on that P. This also means that thread-local data is accessible without the need for locking, and this is exactly what sync.Pool is leveraging here. Let’s have a look at the logic sourrounding the pinning:
// pin pins the current goroutine to P, disables preemption and
// returns poolLocal pool for the P and the P's id.
// Caller must call runtime_procUnpin() when done with the pool.
func (p *Pool) pin() (*poolLocal, int) {
pid := runtime_procPin()
// In pinSlow we store to local and then to localSize, here we load in opposite order.
// Since we've disabled preemption, GC cannot happen in between.
// Thus here we must observe local at least as large localSize.
// We can observe a newer/larger local, it is fine (we must observe its zero-initialized-ness).
s := runtime_LoadAcquintptr(&p.localSize) // load-acquire
l := p.local // load-consume
if uintptr(pid) < s {
return indexLocal(l, pid), pid
}
return p.pinSlow()
}
func indexLocal(l unsafe.Pointer, i int) *poolLocal {
lp := unsafe.Pointer(uintptr(l) + uintptr(i)*unsafe.Sizeof(poolLocal{}))
return (*poolLocal)(lp)
}
A few things to unpack here; Let’s start by defining what local and localSize actually are. Until now, we’ve defined this as some kind of inner pool, but we now need to go into more details. local is a C-style array of poolLocal objects, and localSize is the size of that array. We will get into more details about that poolLocal structure later on. What we need to understand here is that each poolLocal object in that local array is for a given P. As you can see, the call to runtime_procPin returns the id of the processor we’re pinned to - and this pid starts at 0 and grows upwards by increments of one. Put simply, there’s P0, P1, P2 and so on up to GOMAXPROCS, which defines the maximum number of P’s, and that is initialized by default to match the number of CPU cores, and can change at runtime (do you see it comming?).
We’ll look into the initialization of local below, but let’s consider what happens on the happy path first. If the size of local is greater than our P’s pid, this means that we indeed have a matching poolLocal object. indexLocal reconstructs the pointer at the correct offset, and retuns the poolLocal object for our P. This mechanism allows us to get our local pool without using any locks - that’s a very fast path: we’re just pinning, and directly accessing our thread-local variable.
Before going further into the pinSlow fallback path, we need to address the load-acquire/load-consume comments. Here’s the code for LoadAcquintptr:
// this is the code for amd64
//go:nosplit
//go:noinline
func LoadAcquintptr(ptr *uintptr) uintptr {
return *ptr
}
While the nosplit, noinline compiler directives ensure consistency in the execution of the function, in effect we could load-consume p.localSize on i386/amd64, but other architectures such as arm64, mips or riscv have more relaxed memory ordering and need more work, such as using atomic loads.
# this is the code for riscv64
TEXT ·LoadAcquintptr(SB),NOSPLIT|NOFRAME,$0-16
JMP ·Load64(SB)
TEXT ·Load64(SB),NOSPLIT|NOFRAME,$0-16
MOV ptr+0(FP), A0
LRD (A0), A0
MOV A0, ret+8(FP)
RET
The essential thing to understand here is that we want to ensure that we read localSize before we read local, as they are set in the other way around on the slow path.
Now let’s look at the slow path code. The pinSlow method is the fallback path to pin: we go there when our assumption about the size of local is wrong, meaning that our P does not have a matching poolLocal object. This means that either the pool is new, or that GOMAXPROCS was updated and we got some additional P’s.
func (p *Pool) pinSlow() (*poolLocal, int) {
// Retry under the mutex.
// Can not lock the mutex while pinned.
runtime_procUnpin()
allPoolsMu.Lock()
defer allPoolsMu.Unlock()
pid := runtime_procPin()
// poolCleanup won't be called while we are pinned.
s := p.localSize
l := p.local
if uintptr(pid) < s {
return indexLocal(l, pid), pid
}
if p.local == nil {
allPools = append(allPools, p)
}
// If GOMAXPROCS changes between GCs, we re-allocate the array and lose the old one.
size := runtime.GOMAXPROCS(0)
local := make([]poolLocal, size)
atomic.StorePointer(&p.local, unsafe.Pointer(&local[0])) // store-release
runtime_StoreReluintptr(&p.localSize, uintptr(size)) // store-release
return &local[pid], pid
}
pinSlow cannot acquire the lock on the static allPools variable while pinned. Think about it: that would be a recipe for deadlocks. Since our pinned goroutine cannot be preempted, it could be trying to acquire a lock that is held by another goroutine waiting for us to release the P. So pinSlow starts by unpinning the goroutine, acquires the lock, and then re-enter a pinned context. During that time, we’re not protected against preemption, thus two things can happen:
- the runtime could stop the world and run
poolCleanup, but we don’t care, we’re only racing against other goroutines, - another goroutine could acquire the lock before us.
Once we get back to safety, in a pinned context, we need to recheck whether our condition has changed: if we have a matching poolLocal object, we just return it. This means that either another goroutine got this for us, or that we’re not on the same P anymore, and this one’s covered. If we’re still in the previous state, then we correct it. By the way, did you notice that this is the place where we register our pool into the allPools variable?
// If GOMAXPROCS changes between GCs, we re-allocate the array and lose the old one.
size := runtime.GOMAXPROCS(0)
local := make([]poolLocal, size)
atomic.StorePointer(&p.local, unsafe.Pointer(&local[0])) // store-release
runtime_StoreReluintptr(&p.localSize, uintptr(size)) // store-release
return &local[pid], pid
The last 5 lines of pinSlow are doing the initialization work: it build a new slice of poolLocal objects, one per P, and stores the address of the first one into local, and then the size of the slice into localSize (to be consistent with the fast path).
sync.Pool leverages proc pinning to create a fast path for thread-local data consumption, and uses a clever slow path to fix cases where we need to synchronize. The pin method hides all that complexity to the rest of the code - its job is to pin the goroutine to the P, but more importantly to register the pool into the allPools static variable, and do all the heavy-lifting required to return the poolLocal associated with the pinned P.
Poolception
Let’s go deeper: we need to explore the poolLocal structure and understand how it is being manipulated by Put and Get. Here is the poolLocal structure:
// Local per-P Pool appendix.
type poolLocalInternal struct {
private any // Can be used only by the respective P.
shared poolChain // Local P can pushHead/popHead; any P can popTail.
}
type poolLocal struct {
poolLocalInternal
// Prevents false sharing on widespread platforms with
// 128 mod (cache line size) = 0 .
pad [128 - unsafe.Sizeof(poolLocalInternal{})%128]byte
}
poolLocalInternal is in essence what we call the “pool”: it is composed of a private attribute, which is one pool item, and the rest of the items are stored in shared, which is a doubly linked list, used as a Last-in, First-out (LIFO) queue. poolLocal embeds poolLocalInternal, and ensures a 128 bytes padding.
To get a clearer picture of poolLocalInternal, let’s define attributes as:
privateis a single item, ready to be used, for very fast access - this is an optimization;sharedis a local shard of the cache - this is the items we are storing for that cpu core.
Before moving on, let’s talk about the purpose of that padding in poolLocal. We make the general assumption that CPU cache lines are 128 bytes maximum, or a lower power of 2, and the goal is that the poolLocal structure fills one or more cache lines. As we’ve seen previously, p.local is a contiguous block of memory (an array) with poolLocal objects for each P next to each other. False sharing would be very detrimental to the fast path here, as it would mean that for every change a P makes to its poolLocal object, other P’s might need to synchronize cache lines containing their own poolLocal; instead, by making sure cache lines are not shared by multiple poolLocal objects, we prevent this false sharing. I wrote about false sharing in another post.
In other terms, each P can access and modify their own poolLocal object without causing cache invalidation in other cores.
Put, Get
Now that we’ve made this clear, let’s have a look at how Put works:
// Put adds x to the pool.
func (p *Pool) Put(x any) {
if x == nil {
return
}
if race.Enabled {
if fastrandn(4) == 0 {
// Randomly drop x on floor.
return
}
race.ReleaseMerge(poolRaceAddr(x))
race.Disable()
}
l, _ := p.pin()
if l.private == nil {
l.private = x
} else {
l.shared.pushHead(x)
}
runtime_procUnpin()
if race.Enabled {
race.Enable()
}
}
Let’s ignore the race stuff; The code is pretty simple:
- pin, get our
poolLocal; - if
privateis empty, put the item there; - else, put it in
shared, LIFO style; - unpin
…and that’s pretty much it. We could go into details about the implementation of the doubly linked list poolChain is made of, but that’s out-of scope here. All we need to know about this list is what’s said in the comments
Local P can pushHead/popHead; any P can popTail.
You might already have strong assumptions about how Get works by seeing Put and this comment. Let’s get to it:
// Get selects an arbitrary item from the Pool, removes it from the
// Pool, and returns it to the caller.
// Get may choose to ignore the pool and treat it as empty.
// Callers should not assume any relation between values passed to Put and
// the values returned by Get.
//
// If Get would otherwise return nil and p.New is non-nil, Get returns
// the result of calling p.New.
func (p *Pool) Get() any {
if race.Enabled {
race.Disable()
}
l, pid := p.pin()
x := l.private
l.private = nil
if x == nil {
// Try to pop the head of the local shard. We prefer
// the head over the tail for temporal locality of
// reuse.
x, _ = l.shared.popHead()
if x == nil {
x = p.getSlow(pid)
}
}
runtime_procUnpin()
if race.Enabled {
race.Enable()
if x != nil {
race.Acquire(poolRaceAddr(x))
}
}
if x == nil && p.New != nil {
x = p.New()
}
return x
}
Let’s still ignore the race stuff here. Get is simple too:
- pin, get our
poolLocal; - empty
private, and if it was not empty, use that item; - in the event
privatewas empty, popshared, LIFO style, and use that item; - in the event
sharedwas empty, we’ll go down the slow path; - in the event even that did not work, we’ll call
New; - unpin.
There’s a couple interesting things here. This first one is the comment about popHead() - what does it mean, really? This is a design choice: we want to reduce temporal locality of reuse, meaning that we choose to reuse latest allocations, and let the oldest ones fade out. The second one is about the access pattern used to read private - memory ordering is ensured, the intent is clear, and we do not introduce useless branching - neat.
There’s just one last thing to cover here, it’s the slow path. This happens when our thread-local pool is empty. By now, you can easily guess what’s going to happen here, right? As suggested by the earlier comment (“any P can popTail”), we’re going to try to steal an item from other P’s. If that does not work, we’ll try to look in all the victim pools.
func (p *Pool) getSlow(pid int) any {
// See the comment in pin regarding ordering of the loads.
size := runtime_LoadAcquintptr(&p.localSize) // load-acquire
locals := p.local // load-consume
// Try to steal one element from other procs.
for i := 0; i < int(size); i++ {
l := indexLocal(locals, (pid+i+1)%int(size))
if x, _ := l.shared.popTail(); x != nil {
return x
}
}
// Try the victim cache. We do this after attempting to steal
// from all primary caches because we want objects in the
// victim cache to age out if at all possible.
size = atomic.LoadUintptr(&p.victimSize)
if uintptr(pid) >= size {
return nil
}
locals = p.victim
l := indexLocal(locals, pid)
if x := l.private; x != nil {
l.private = nil
return x
}
for i := 0; i < int(size); i++ {
l := indexLocal(locals, (pid+i)%int(size))
if x, _ := l.shared.popTail(); x != nil {
return x
}
}
// Mark the victim cache as empty for future gets don't bother
// with it.
atomic.StoreUintptr(&p.victimSize, 0)
return nil
}
By now, this code is dead simple to you, but you need to read it knowing that it is called in pinned context. We’re reusing logic from the pin method to popTail the shared attribute of all local pools. If that does not work, we’ll try to look into the victim cache, but approximately just once (concurrent tries are doing the same). After that try, we’re setting victimSize to 0, removing that option for next gets until we hit the next GC cycle.
That’s it, now you know everything there is to know about sync.Pool. Or do you? Definitely not.
Handling byte buffers efficiently
By now, you may feel like a sync.Pool expert. Here’s the harsh truth: you’re probably not, and I’m not either.
Let’s consider this code:
package main
import "sync"
var pool sync.Pool
func init() {
pool = sync.Pool{
New: func() any {
return make([]byte, 4<<10)
},
}
}
func main() {
b := pool.Get().([]byte)
// ...do something with b
_ = b
pool.Put(b) // this is line 21
}
Let’s forget that this exact code is useless, the idea is that we’re reusing some fixed length byte buffers through our application. Neat, right?
❯ go run -gcflags="-m" a.go
# command-line-arguments
./a.go:7:6: can inline init.0
./a.go:9:8: can inline init.0.func1
./a.go:9:8: func literal escapes to heap
./a.go:10:15: make([]byte, 4 << 10) escapes to heap
./a.go:10:15: make([]byte, 4 << 10) escapes to heap
./a.go:21:11: b escapes to heap
Well, that is a lot better than not reusing buffers at all, but still not perfect. Above we get an escape analysis red flag: although we’re directly reusing a buffer, it is escaping to the heap each time we are putting it back in the pool. Think about it: b is a []byte, hence we have a local copy of the slice header. By passing it to Put, we’re making it escape to the heap.
Now let’s consider this code:
package main
import "sync"
var pool sync.Pool
func init() {
pool = sync.Pool{
New: func() any {
b := make([]byte, 4<<10)
return &b
},
}
}
func main() {
bPtr := pool.Get().(*[]byte)
b := *bPtr
// ...do something with b
_ = b
pool.Put(bPtr)
}
Now the pool contains pointers to byte buffers. We get a pointer, dereference it for use, but pass the original pointer back to the pool when releasing.
# command-line-arguments
./a.go:7:6: can inline init.0
./a.go:9:8: can inline init.0.func1
./a.go:10:4: moved to heap: b
./a.go:9:8: func literal escapes to heap
./a.go:10:13: make([]byte, 4 << 10) escapes to heap
Much better, right? That’s the spirit: test your assumptions.
Conclusion
Go’s sync.Pool elegantly manages memory and can optimize performance in highly concurrent applications. It feels like a masterpiece of simplicity by design, and I hope this dive helped you understand it better. Now go have fun!